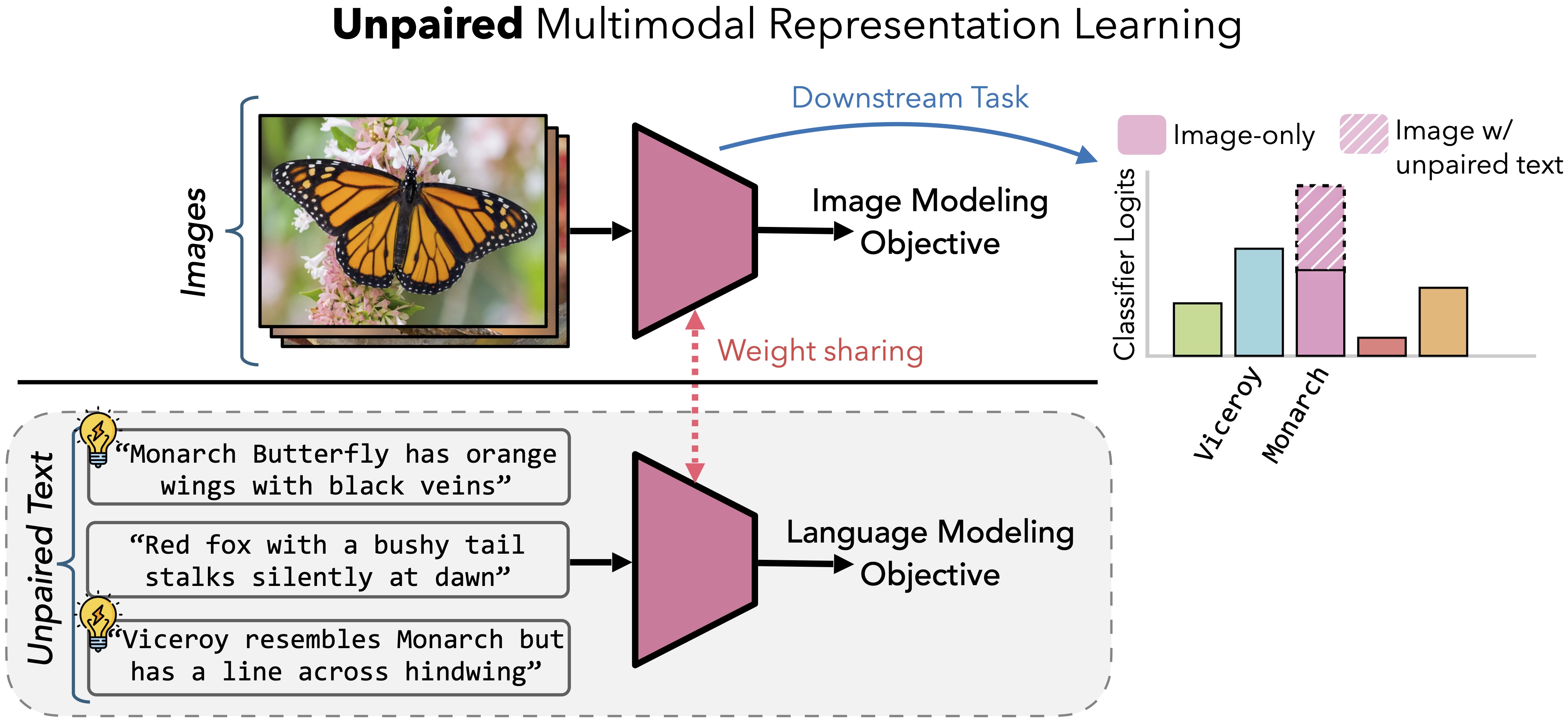
Unpaired Multimodal Representation Learning.
Text provides complementary information beyond images, even when not paired directly;
We introduce Unpaired Multimodal Learner (UML) whereby sharing model weights across modalities
(e.g., image and text) extracts synergies and enhances unimodal representations, outperforming methods
that rely only on a single modality (such as images above).
Abstract
Traditional multimodal learners find unified representations for tasks like visual
question answering, but rely heavily on large paired datasets. However, an over-
looked yet potentially powerful question is: can one leverage auxiliary unpaired unimodal
multimodal data to directly enhance representation learning in a target modality?
We introduce UML:Unpaired Multimodal
Learner, a modality-agnostic training paradigm in which a
single model alternately processes inputs from
different modalities while sharing parameters across them. This design exploits the
assumption that different modalities are projections of a shared underlying reality,
allowing the model to benefit from cross-modal structure without requiring explicit
pairs. Theoretically, under linear data-generating assumptions, we show that
unpaired auxiliary data can yield representations strictly more informative about
the world than unimodal training. Empirically, we show that using unpaired data
from auxiliary modalities—such as text, audio, or images—consistently improves
downstream performance across diverse unimodal targets such as image and audio.
Unpaired Multimodal Representation Learning
Many multimodal methods assume access to paired samples $(x_i,y_i)\sim P_{X,Y}$, e.g.,
image–caption or audio–video pairs. Encoders $f_{X}:\mathcal{X}\!\to\!\mathcal{Z}$ and
$f_{Y}:\mathcal{Y}\!\to\!\mathcal{Z}$ are trained so that matched pairs are close in a shared
space $\mathcal{Z}$, typically via contrastive alignment, fusion/reconstruction, or generative
translation. While effective, this paradigm requires costly, curated correspondences and can
inherit biases from pairing pipelines.
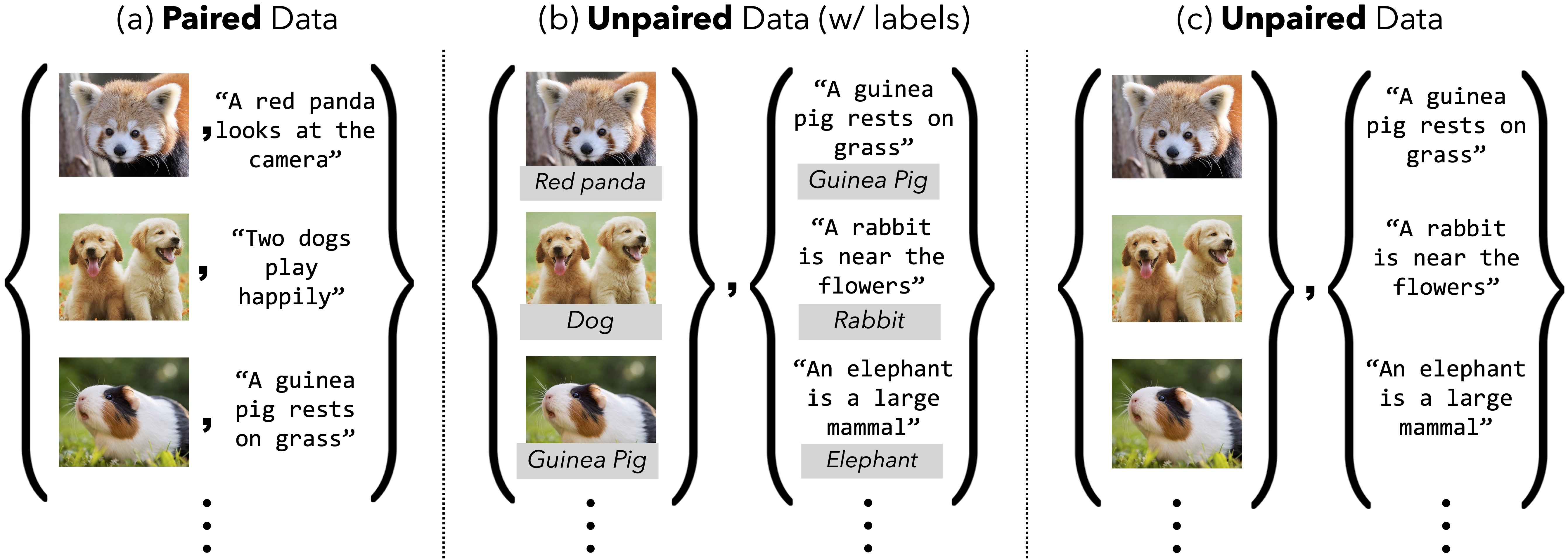
We instead study unpaired multimodal representation learning. Here, we only observe
datasets drawn from marginal distributions $P_X$ and $P_Y$; the joint $P_{X,Y}$ and any $(x,y)$
correspondences are unknown.
The aim is to learn encoders $f_X$ and $f_Y$ that capture shared structure of the underlying reality
without ever inferring alignments, using partially paired data, or assuming pre-aligned embeddings.
We examine two regimes of unpaired data: (a) with labels where data from each modality
has contains its class labels but there are no cross-modal correspondences, and (b) fully unpaired,
where neither labels nor correspondences are available.
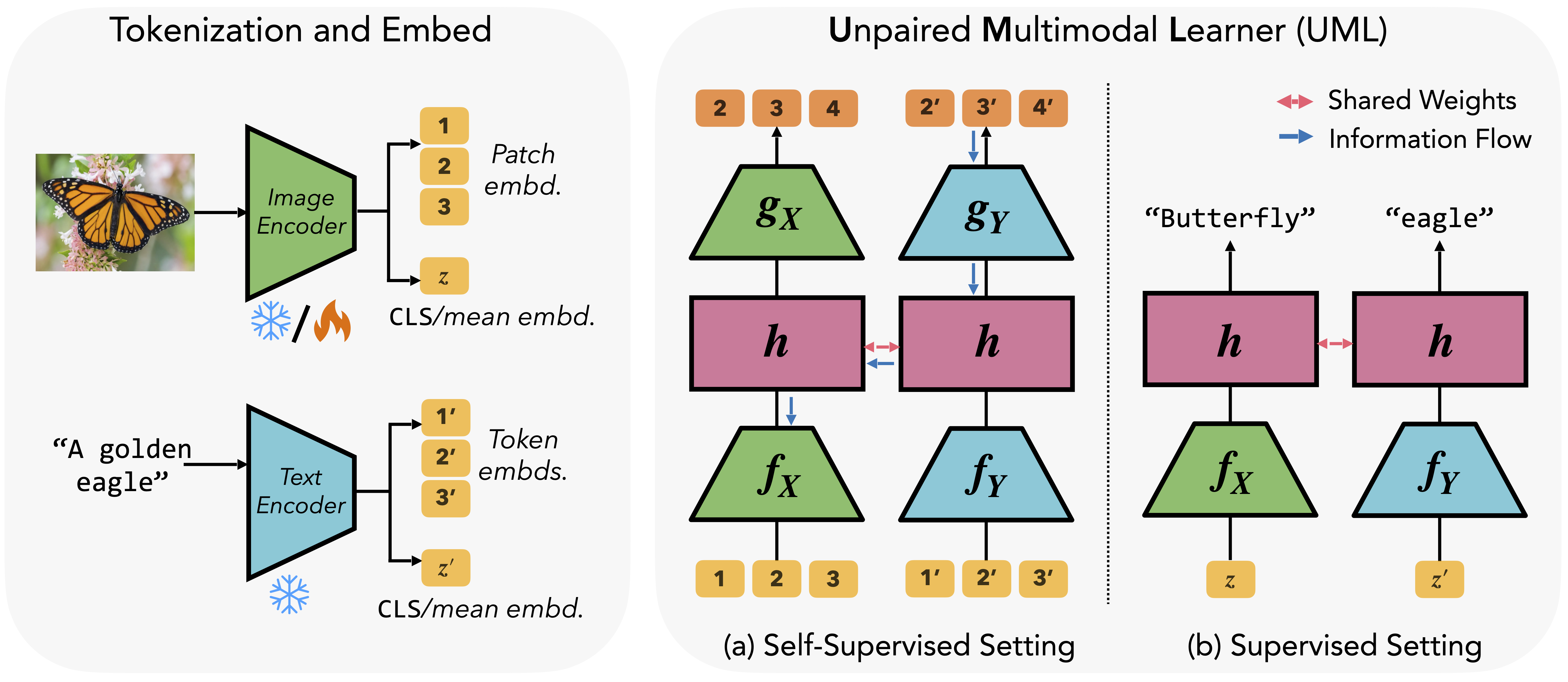
Unpaired Multimodal Learner (UML)
The core idea of Unpaired Multimodal Learner (UML) is remarkably simple:
share weights across modalities.
If images, text, or audio are all different views of the same world, then forcing them
through shared weights can extract synergies by accumulating training gradients on the same parameters,
even without paired data. The training proceeds as follows:
Encode. Each modality (image, text, audio) is first converted to embeddings with its own encoder ($f_X$, $f_Y$) which are
either initialized randomly or from a pretrained model.
Shared Backbone. All embeddings, regardless of source, are passed through the same shared network $h$.
This is the sole coupling between modalities and the locus of cross-modal transfer.
Training Supervision.
Self-supervised: Each modality has its own decoder to
either reconstruct inputs or predict next patches/tokens depending on the modality.
Supervised: A single shared classifier predicts class labels for each modality.
Thus in both regimes, athough supervision is modality-specific, the shared backbone $h$ receives
updates from both modalities. Consequently, gradients from $h$ also flow into $f_X$,
effectively transferring information from $f_Y$ and thus $\mathcal{Y}$ even without paired samples.
At inference, we drop the auxiliary branches and use the output embedding from $h$ as the representation for the target modality,
training a simple linear probe on topfor downstream tasks.
Results
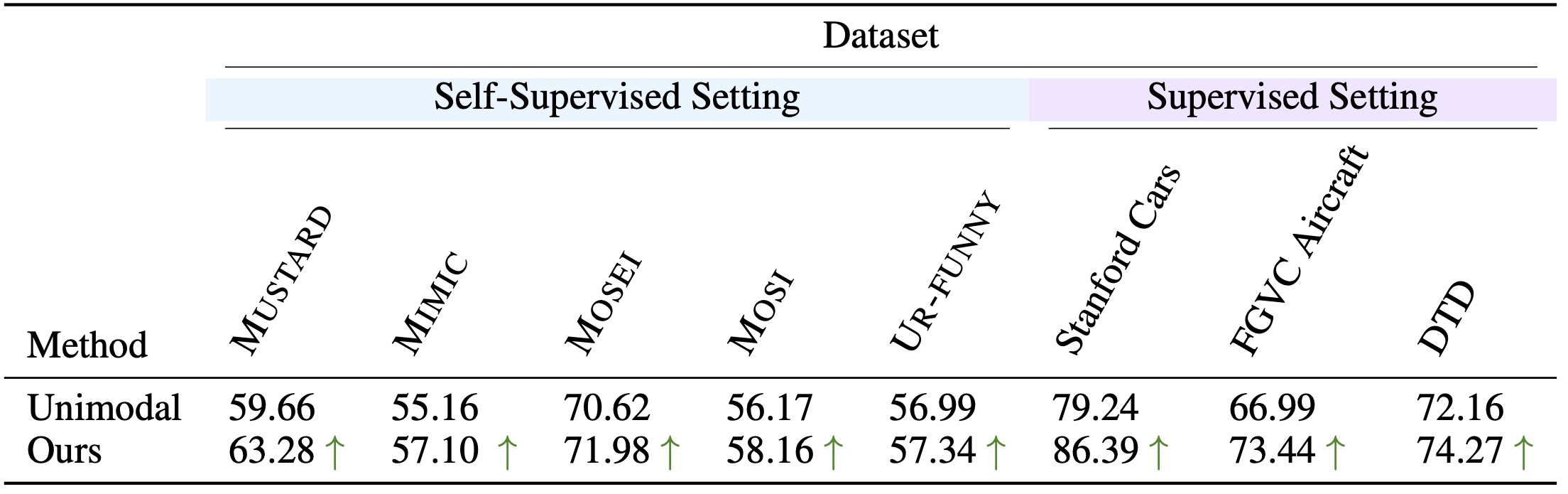
1. Auxiliary Text Data Improves Image Representations
We evaluate UML in two regimes: (a) a self-supervised setting using
multimodal benchmarks from MultiBench dataset; (b) in supervised setting
where per-modality labels are available but no cross-modal correspondences exist, on
standard visual benchmarks such as Stanford Cars, FGVC Aircraft and DTD.
In both regimes, UML consistently outperforms unimodal baseline (image only),
with the largest gains on fine-grained tasks such as Stanford Cars and FGVC Aircraft.
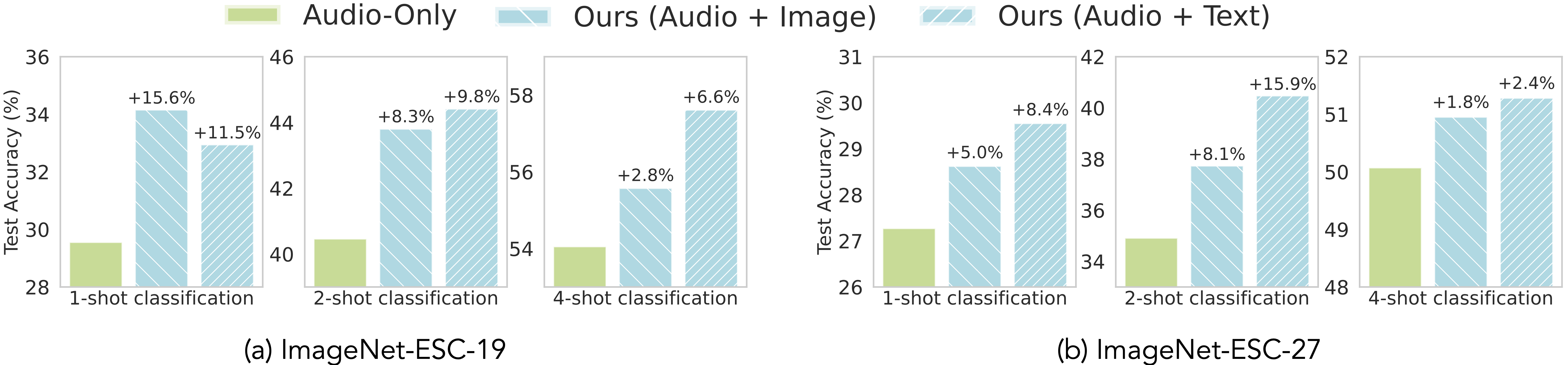
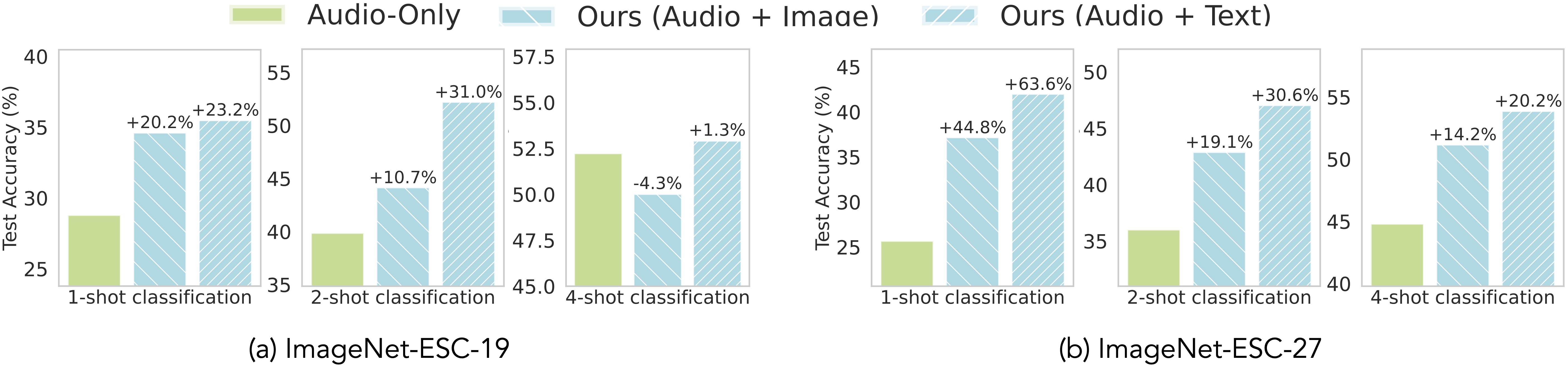
2. Auxiliary Image and Text Data Improves Audio Representations
We extend UML to an audio–vision–text setting using the ImageNet-ESC benchmark,
which links ImageNet objects and captions with ESC-50 environmental sounds.
The benchmark has two versions: ImageNet-ESC-27 and ImageNet-ESC-19. UML consistently improves
audio classification using unpaired image and text samples on both
ImageNet-ESC-19 and ImageNet-ESC-27 benchmarks, with the largest gains when using CLIP's aligned encoders.
Auxiliary Image and Text Data Improves Audio Representations. UML improves audio classification using unpaired image and text samples on both
ImageNet-ESC-19 and ImageNet-ESC-27 benchmarks when trained on top of DINOv2 VIT-S/14 and OpenLLaMa-3B.
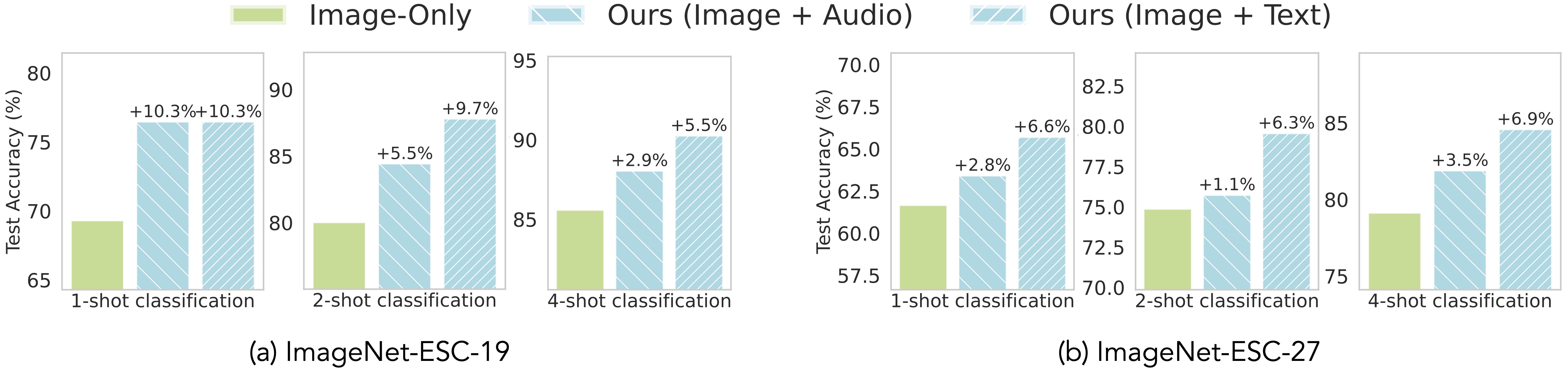
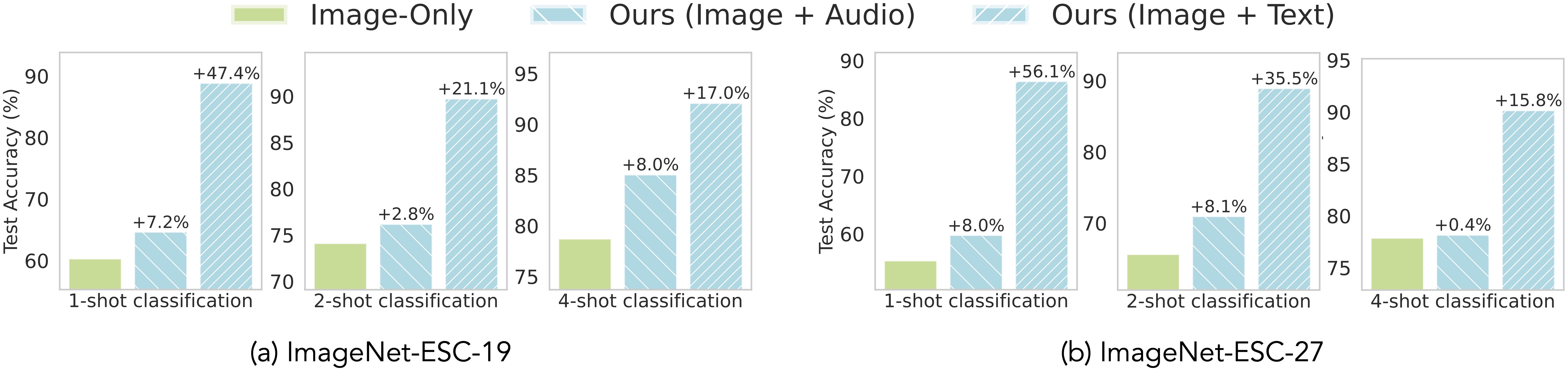
Auxiliary Audio and Text Data Improves Image Representations. UML improves image classification using unpaired audio and text samples on both
ImageNet-ESC-19 and ImageNet-ESC-27 benchmarks when trained on top of DINOv2 VIT-S/14 and OpenLLaMa-3B.
Auxiliary Image and Text Data Improves Audio Representations. UML improves audio classification using unpaired image and text samples on both
ImageNet-ESC-19 and ImageNet-ESC-27 benchmarks when trained on top of CLIP.
Auxiliary Audio and Text Data Improves Image Representations. UML improves image classification using unpaired audio and text samples on both
ImageNet-ESC-19 and ImageNet-ESC-27 benchmarks when trained on top of CLIP.
Having shown that unpaired modalities enhance representation learning and generalization,
we now ask a more fundamental question: what is the relative value of each modality?
If images and text are different views of the same semantic space, can we measure
their exchange rate i.e. how many words is an image worth?
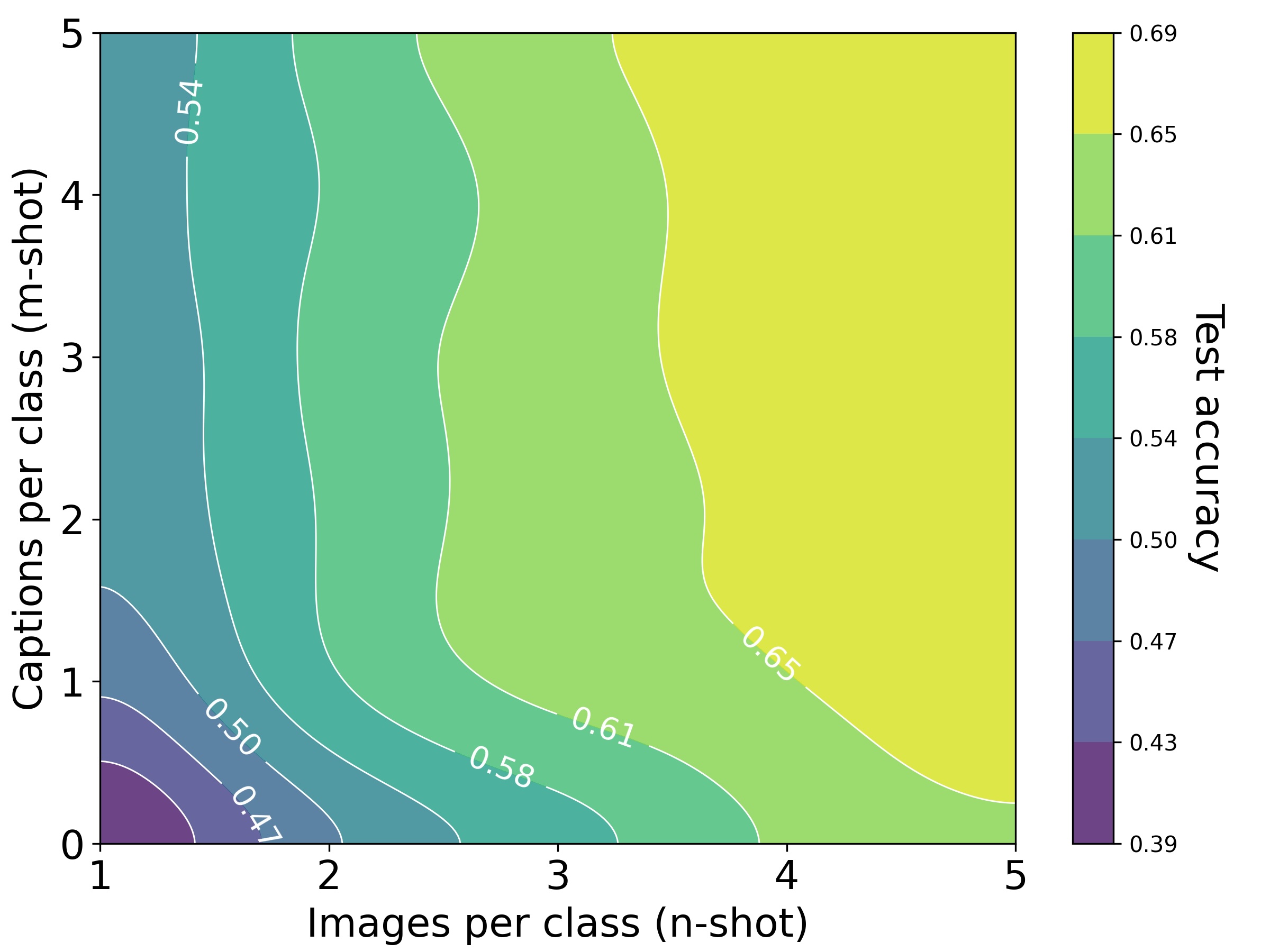
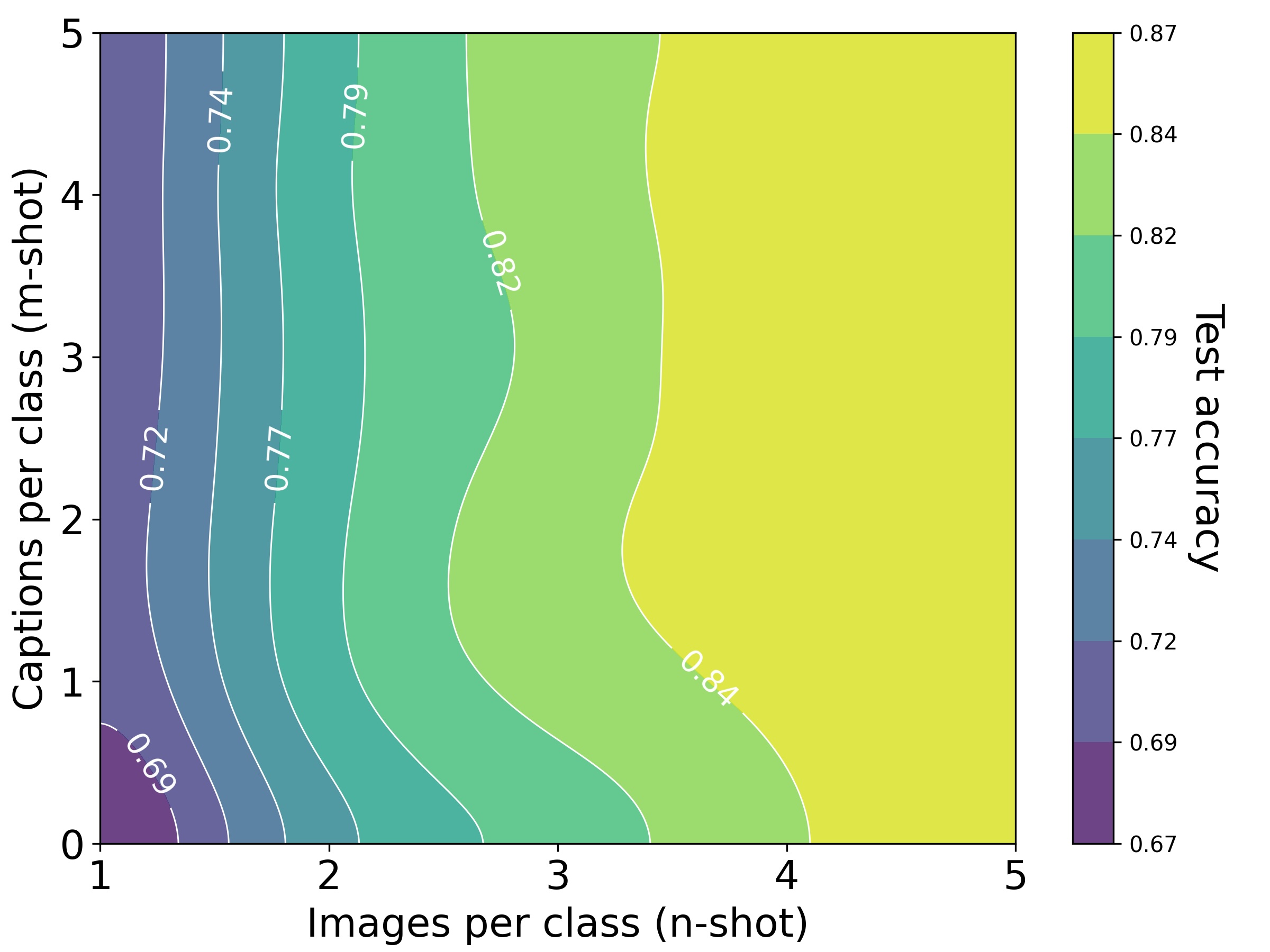
On Oxford-Pets, test accuracy isolines reveal that an aligned CLIP encoder equates
one image to about 228 words, whereas with unaligned DINOv2 + OpenLLaMA,
the ratio rises to $\approx$ 1034 words.
Indeed, in some cases, an image may quite literally be worth a thousand words.
1 image $\approx$ 228 words for CLIP
1 image $\approx$ 1034 words for DINOv2
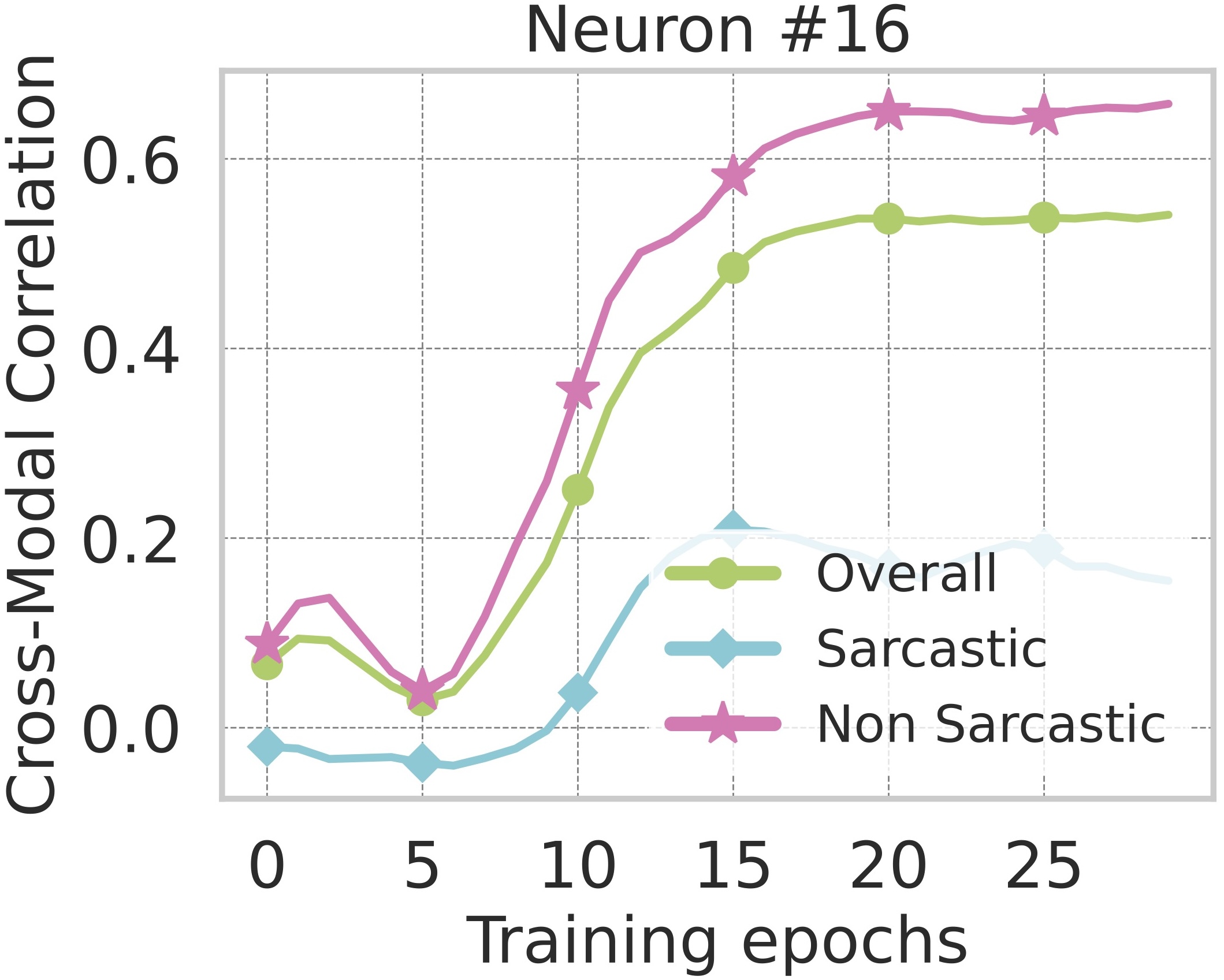
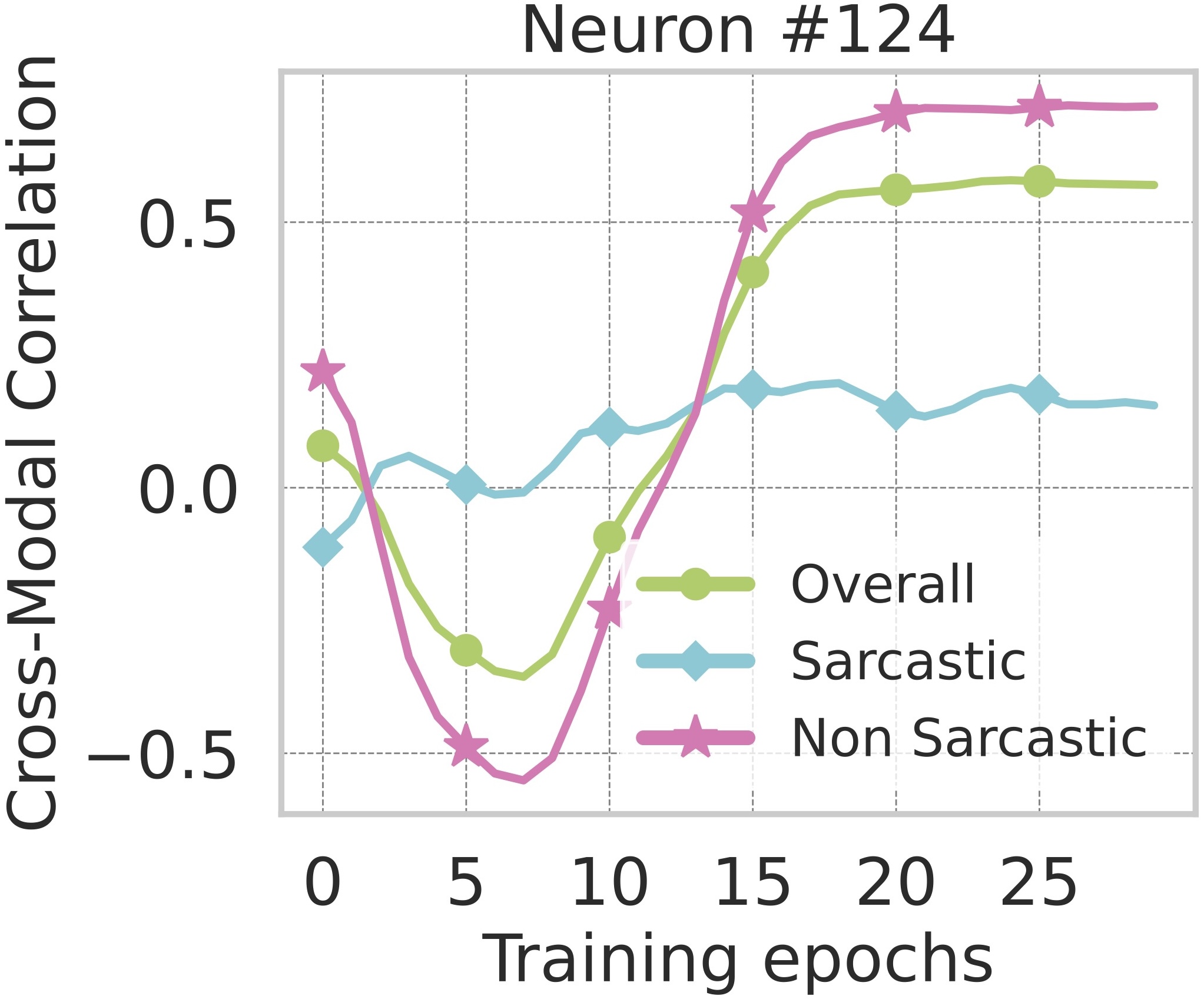
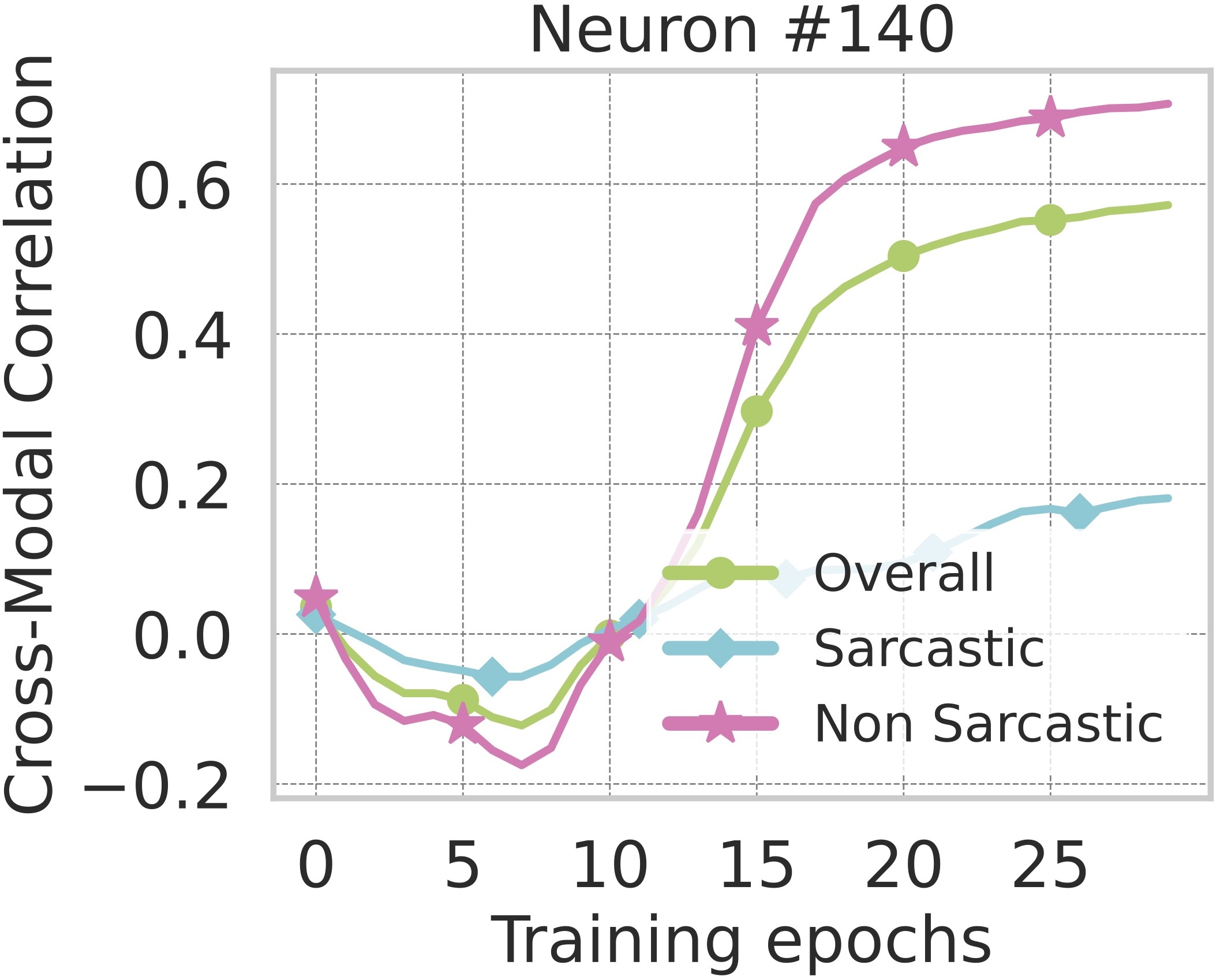
4. Existence of Multimodal Neurons
While the previous section quantified the exchange rate between modalities, our next question concerns the mechanism that
enables such exchange. Models like CLIP, trained with paired image–text supervision, are known to develop multimodal neurons: units that respond coherently
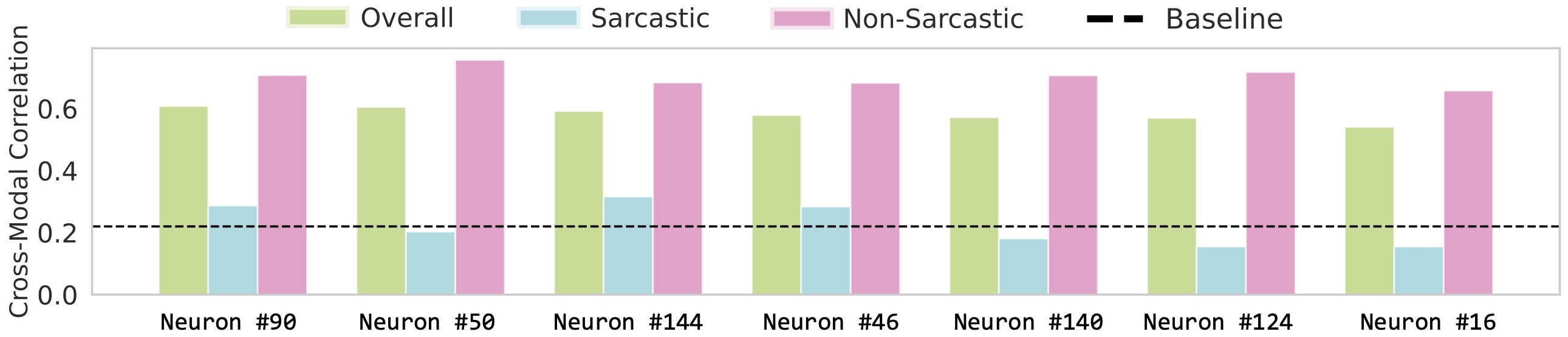
to the same concept across both modalities. We report the emergence of similar multimodal neurons, without any paired supervision i.e. when the model is exposed only to unpaired data.
As shown below, several neurons exhibit strong cross-modal coupling between vision and text, significantly higher than the highest correlation across neurons for an
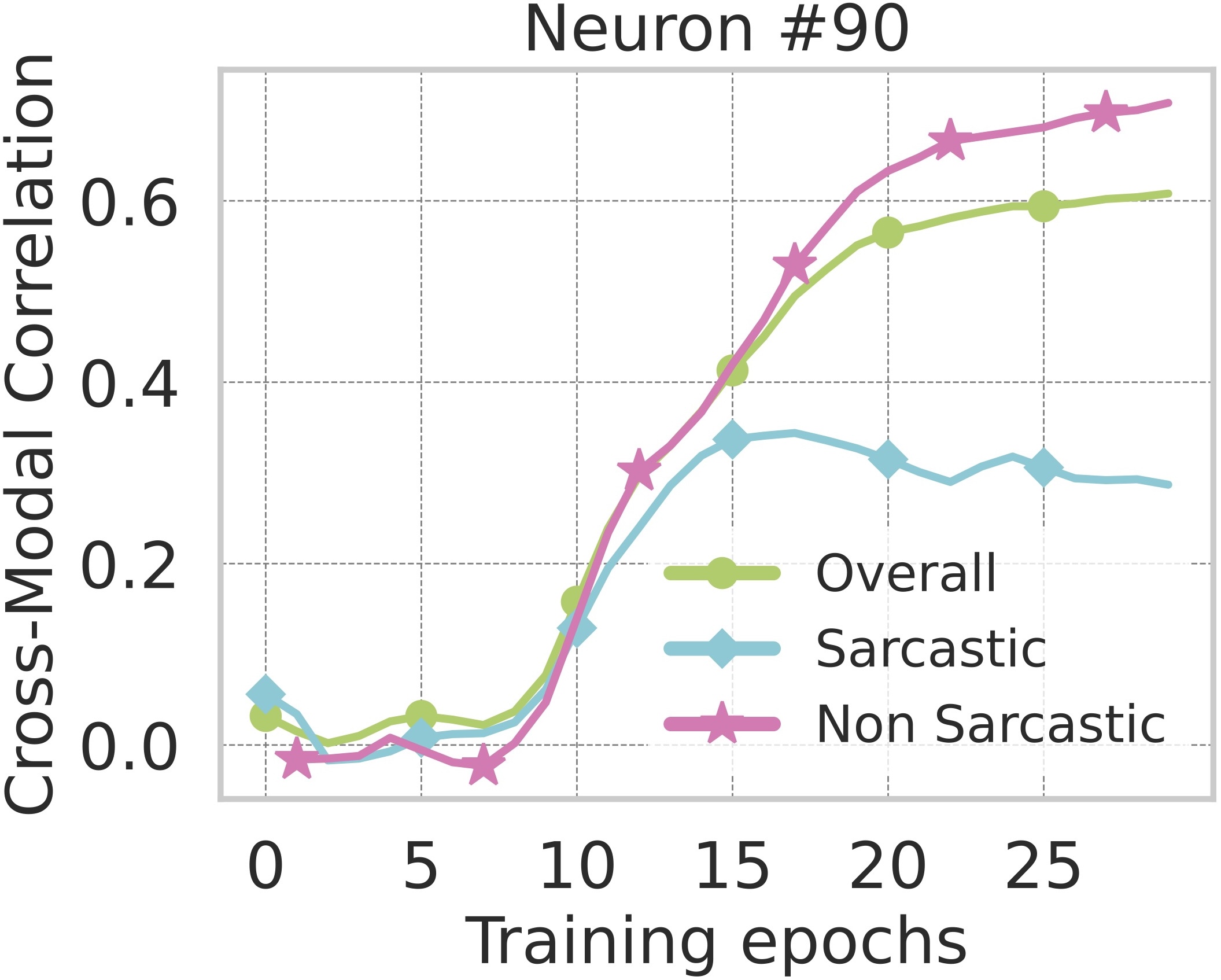
untrained network (baseline). This coupling steadily improves with training epochs, indicating that the model progressively infers more correspondences between modalities all
without any paired supervision.
Existence of Multimodal Neurons without Paired Supervision.
Most neurons exhibit strong cross-modal correlation and specifically higher alignment for non-sarcastic samples,
where visual and verbal cues are naturally congruent.
Evolution of Cross-Modal Correlation with Training Steps.
As training progresses, neurons exhibit strong cross-modal correlation, suggesting that the model learns to implicitly align modalities.
Please refer to our paper for more results, ablations, and visualizations!
Acknowledgements
This research was sponsored by the Department of the Air Force
Artificial Intelligence Accelerator under Cooperative Agreement Number FA8750-19-2-1000,
and in part by the NSF AI Institute TILOS (NSF CCF-2112665) and the Alexander von Humboldt Foundation.
This work was also supported by a Packard Fellowship to P.I., and by ONR MURI grant N00014-22-1-2740.
Sharut Gupta is supported by the MathWorks Engineering Fellowship.
Shobhita Sundaram is supported by an NSF GRFP fellowship. The views and conclusions contained
in this document are those of the authors and should not be interpreted as representing the
official policies, either expressed or implied, of the Department of the Air Force or the U.S.
Government. The U.S. Government is authorized to reproduce and distribute reprints for Government
purposes, notwithstanding any copyright notation herein.
Citation
@inproceedings{sharut2025better,
title={Better Together: Leveraging Unpaired Multimodal Data for Stronger Unimodal Models},
author={Gupta, Sharut and Sundaram, Shobhita and Wang, Chenyu and
Jegelka, Stefanie and Isola, Phillip},
journal={arXiv preprint arXiv:2510.08492},
year={2025}
}